Source compile process trong C++
in Programming on C++
Dưới đây là sơ đồ về quá trình Source compile process trong C++, nó mô tả tổng quan về tất cả các giai đoạn tiền xử lý đến biên dịch và liên kết để cho ra được file thực thi/thư viện cuối cùng:
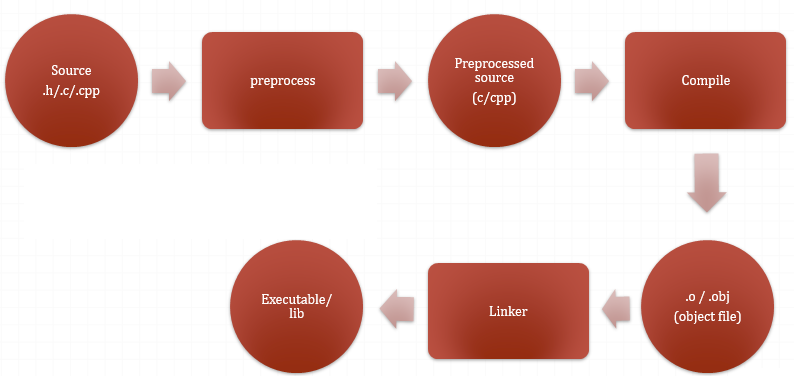
Từ source code ban đầu gồm các file c/cpp và các file header sẽ thông qua quá trình tiền xử lý để tạo ra duy nhất các file c/cpp. Các file này mới thực sự được sử dụng trong quá trình biên dịch sau này, các file header chỉ được sử dụng duy nhất để dán toàn bộ code của nó vô vị trí khai báo inlcude trong file c/cpp và thực thi macro tương ứng mà thôi. Ở đây ta có 1 chú ý nhỏ là các chỉ thị sau #(như #include, #define…) đều thuộc về quá trình tiền xử lý, sau giai đoạn này thì nó sẽ bị thay thế hoặc gở bỏ. Sau khi tạo ra các file c/cpp cuối cùng nhờ tiền xử lý, nó sẽ được compiler biên dịch ra các file object(.o hoặc .obj), mỗi file c/cpp sẽ được biên dịch ra các file object tương ứng. Sau khi biên dịch thành công thì đến linker sẽ sử dụng các file objects để kết nối chúng lại để cho ra file thực thi hoặc file thư viện.
Tiếp theo chúng ta sẽ đi khảo sát cụ thể từng giai đoạn trong quá trình Source compile process, ta chia làm 3 giai đoạn chính là tiền xử lý(preprocess), biên dịch(compile) và link(linker).
Preprocess - Chuẩn bị
Giai đoạn này còn gọi là giai đoạn chuẩn bị, các cấu hình biên dịch chương trình nói chung thường được áp dụng ở giai đoạn này như việc cấu hình để biên dịch source code trên các nền tản khác nhau. Các file code của chúng ta bao gồm 2 loại chính là các file source c/cpp và các file header. Các file c/cpp thường sẽ chứa các thực thi của các classes hoặc hàm trong khi các file headers sẽ chứa các định nghĩa của classes hoặc nguyên mẫu hàm. Công việc của tiền xử lý ở đây chỉ đơn thuần là xử lý code của chúng ta dựa trên các chỉ thị sau #, chúng sẽ không quan tâm nội dung code của chúng ta viết gì, có đúng cú pháp không mà chỉ dựa vào các thị sau # để xử lý chay code để tạo ra các file c/cpp cuối cùng. Ví dụ, ta có 2 file là another.h và another.cpp chứa nội dung lần lượt như sau:
another.cpp
#include "another.h"
void func(int n){
printf("Number is %d\n", n);
}
int main(){
func(NUM);
}
another.h
#define NUM 10
void func(int n);
Sau quá trình tiền xử lý thì toàn bộ nội dung của file another.h sẽ được dán trực tiếp vào khai báo include của another.cpp, tiếp theo define sẽ thay thế toàn bộ các NUM bằng 10, kết quả cuối cùng ta có file _another.cpp như sau:
void func(int n);
void func(int n){
printf("Number is %d\n", n);
}
int main(){
func(10);
}
Cuối cùng file _another.cpp sẽ được sử dụng để biên dịch ở bước tiếp theo. Chú ý rằng ở bước tiền xử lý này chỉ xử lý chay trên text dựa trên các chỉ dẩn tiền xử lý sau #. Ví dụ tiếp theo sẽ cho thấy tiền xử lý xử lý thay dữ liệu như thế nào, ta chỉnh sửa nội dung 2 file another.h và another.cpp lại như sau:
another.cpp
#include "another.h"
int n){
printf("Number is %d\n", n);
}
int main(){
func(NUM);
}
another.h
#define NUM 10
void func(
Kết quả sau tiền xử lý như sau:
void func(int n){
printf("Number is %d\n", n);
}
int main(){
func(10);
}
Như đã thấy thì chương trình của chúng ta vẩn bình thường sau quá trình tiền xử lý(mặt dù trong source code gốc thì không bình thường cho lắm). Ở đây có nhiều người đọc source code của chúng ta và bảo nó bị lỗi cú pháp ở khai báo nguyên mẫu hàm(another.h) và định nghĩa hàm(another.cpp), đúng là sai cú pháp nhưng sau khi build thì vẩn chạy bình thường, đây cũng là 1 cách để mã hóa code cho những người thích chơi trội, mặt trái của nó thì chắc ai cũng nhận ra đó là khó debug. Các vấn đề thường phát sinh nếu không nắm chắc hoạt động của quá trình tiền xử lý là include vòng(nghĩa là file A include file B và file B cũng include lại file A mà không có chỉ dẩn để tiền xử lý chỉ include 1 lần duy nhất), redefine các các hàm(trong file header chứa định nghĩa hàm A, file cpp include file header đó và trong file cpp này lại cũng định nghĩa hàm A) và 1 số lỗi ngớ ngẩn khi dùng define(ví dụ như #define MAX 10; trong hàm main ta sử dụng int arr[MAX];). Qua đây ta cũng hiểu tại sao trong các file header chỉ nên chứa các định nghĩa nguyên mẫu hàm và định nghĩa classes. Sau quá trình tiền xử lý thì chỉ còn lại các file c/cpp được sử dụng cho quá trình compile, các file header sẽ không tham gia vào quá trình này.
Compile - Tạo object files
Quá trình biên dịch sẽ cho ra các file objects với nội dung khác nhau tùy theo từng nền tảng(windows, linux…) mà compiler đang chạy vì thế nên nếu ta muốn chương trình chạy trên một nền tản khác thì phải biên dịch lại toàn bộ mã nguồn. Ở bước biên dịch sẽ tiến hành kiểm tra cú pháp và tạo ra các files object tương ứng với từng file c/cpp được biên dịch. Bước kiểm tra cú pháp sẽ đưa ra các cảnh báo hoặc thông báo lỗi khi cú pháp chương trình nếu không hợp lệ. Khi có thông báo lỗi hoặc cảnh báo thì ở output thường sẽ hiển thị số dòng và tên file chứa lỗi hoặc cảnh báo đó. Bên dưới là 1 ví dụ về các cảnh báo được đưa ra khi biên dịch source code trong IDE CodeBlocks:

Ở quá trình biên dịch, các file c/cpp sẽ được biên dịch ra mã máy là các files object riêng lẻ(thường có đuôi là .o hoặc .obj) nhưng chưa quan tâm đến các liên kết giữa các file objects này với nhau. Ta có 1 ví dụ nhỏ như sau, chương trình của chúng ta chỉ chứa 1 file main.cpp duy nhất có nội dung như bên dưới:
void func(int n);
int main(){
func(10);
}
Dể thấy chương trình này thiếu phần định nghĩa của hàm func. Nhưng giai đoạn compile lại thành công và tạo ra file object, lý do là ta đã khai báo nguyên mẫu hàm func vì thế đến đây trình biên dịch biết rằng có 1 hàm void func(int) trong chương trình(nằm ở đâu thì chưa biết) do đó giai đoạn biên dịch main.cpp diễn ra thành công. Lỗi sẽ phát sinh trong giai đoạn tiếp theo, giai đoạn linker.
Linker - Liên kết object files
Đây là giai đoạn cuối cùng để tạo ra file thực thi hoặc thư viện. Quá trình này sẽ liên kết các files object và kiểm tra các ràng buộc, phụ thuộc giữa chúng. Như ví dụ bên trên, sau khi giai đoạn biên dịch thành công thì 1 file object được tạo ra, đến quá trình link thì linker sẽ tìm kiếm phần định nghĩa của hàm func trong tất các các files object, trong trường hợp ví dụ ở trên thì chỉ có 1 file object và dĩ nhiên là không chứa định nghĩa hàm func vì thế 1 lỗi sẽ được thông báo ra output và quá trình biên dịch chương trình thất bại. Lỗi sẽ được hiển thị như sau(IDE codeblocks):

Ta có ví dụ như sau, file another.cpp và file main.cpp chứa nội dung như bên dưới:
another.cpp
#include <stdio.h>
void func(int n){
printf("%d\n", n);
}
main.cpp
void func(int n);
int main(){
func(10);
}
Sau giai đoạn biên dịch thì 2 file objects được tạo ra là another.o và main.o, đến giai đoạn linker thì trình linker sẽ nối 2 files object này lại với nhau để tạo ra file thực thi cuối cùng và kiểm tra các phụ thuộc và ràng buộc giữa chúng. Cụ thể là tại main.o sẽ kiểm tra xem phần định nghĩa hàm func đang nằm ở đâu trong tất cả các files object, nó sẽ tìm thấy ở file another.o và link định nghĩa của hàm func ở đó với main.o, cuối cùng quá trình build thành công. Các lỗi thường phát sinh trong giai đoạn này là các lỗi về thiếu định nghĩa(hàm hoặc classes…) hoặc định nghĩa nhiều lần 1 hàm hoặc classes…
Tóm lại Như đã thấy thì quá trình biên dịch từ source code sang file thực thi hoặc thư viện khá dễ dàng nhưng việc biên dịch ngược lại thì sẽ khá khó khăng(nhưng không phải là không thể). Nắm được các bước biên dịch chương trình từ reprocess -> compile -> linker sẽ giúp ta giảm thiểu được các lỗi phát sinh trong quá trình biên dịch(nói chung) và dể dàng debug khi biết được lỗi đó là do giai đoạn tiền xử lý, biên dịch hay linker. Đây chính là lợi ích trong việc debug. Việt tách code ra thành các file source khác nhau còn giúp tăng tốc trong giai đoạn compile vì khi ta chỉnh sửa 1 file thì chỉ file đó mới được biên dịch lại ra file object thay vì phải biên dịch lại toàn bộ nếu ta chỉ code trong 1 file. Đều này có ý nghĩa trong các dự án lớn khi mà source code lên tới hàng ngàn hàng triệu dòng thì tăng tốc trong quá trình biên dịch là điều vô cùng quan trọng giúp tăng tốc debug và build ra bản release. Đây chính là lợi ích trong việc tăng tốc biên dịch. Như đã biết thì các hàm inline sẽ thay thế phần định nghĩa của nó vào nơi mà nó được sử dụng, hiểu nôm na là nội dụng của hàm inline sẽ được paste thằng vào nơi mà nó được gọi. Quá trình này diễn ra trong giai đoạn biên dịch, toàn bộ mã máy của hàm inline đó sẽ được paste vào lời gọi hàm, chú ý rằng không phải khai báo inline nào cũng được đối xử như 1 hàm inline thực thụ vì trình biên dịch sẽ kiểm tra hàm có khai báo inline có phù hợp với các điều kiện mà nó đặt ra hay không, nếu không phù hợp thì nó đối xử như với hàm bình thường. Dưới đây là 1 ví dụ về việc hàm inline được xử lý trong quá trình biên dịch: ta có 2 file là another.cpp và main.cpp lần lượt có nội dung như sau:
another.cpp
#include <stdio.h>
void func(int n){
printf("%d\n", n);
}
main.cpp
inline void func(int n);
int main(){
func(10);
}
Khi biên dịch chương trình trên thì ta sẽ nhận được 1 warning như sau:

Khi biên dịch main.cpp thì trình biên dịch sẽ tìm phần định nghĩa của hàm func để kiểm tra xem có nên đối xử như 1 hàm inline hay không và dĩ nhiên là nó không tìm thấy phần định nghĩa của func trong main.cpp vì thế 1 cảnh báo được đưa ra với nội dung là hàm hàm inline này được sử dụng mà lại chưa được định nghĩa(trong khi phần định nghĩa của nó nằm ở file another.cpp). Vì không tìm thấy phần định nghĩa của func trong main.cpp nên nó phải đối xử với func như 1 hàm bình thường nghĩa là công việc tìm kiếm định nghĩa của func sẽ được giao cho giai đoạn linker. Thông qua đây ta chú ý rằng hàm inline phải được định nghĩa cùng với nơi mà nó sử dụng hoặc trong file header nếu không thì nó cũng sẽ được đối xử như các hàm bình thường khác, đây cũng là 1 trong những lý do vì sao mà các phương thức trong class nếu được thực thi ngay trong định nghĩa class thì mặt định là hàm inline. Và đây chính là lợi ích trong việc tối ưu code.
Ta thấy rằng quá trình tiền xử lý, biên dịch và nối đều thực hiện các công việc khác nhau, output của giai đoạn này là input của giai đoạn kia. Thông thường trong các chương trình biên dịch đều bao gồm cả linker nên khi nói biên dịch một chương trình ta có thể hiểu là tạo các file objects(reprocess -> compile) hoặc tạo file thực thi/thư viện(reprocess -> compile -> linker), tùy vào từng ngữ cảnh cụ thể.